2008/02/20
ロカポーターのしくみ(5)
5.可変精度の例
前回のデータの途中部分、電車の駅の部分は、駅であることが分かれば良いので200mほどの精度でも十分でしょう。この例では手を抜いて本当に駅だけですが、途中経路の形をもう少しこまかく(たとえば高速道路のカタチで)取りたいというような場合、重要度の低い部分を非可逆圧縮にして精度を落とすことで、もう少し圧縮できるようになります。
駅の部分だけ200mの精度(4桁にコード化したもの)にしてみましょう。
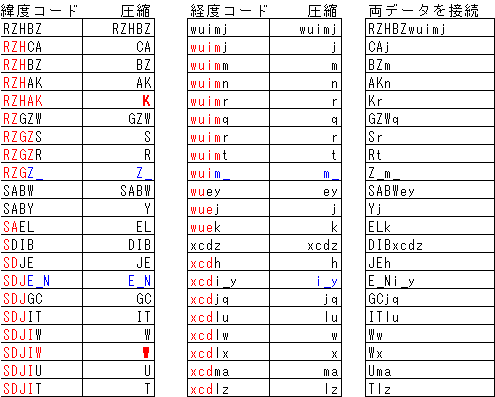
ここで、青字にしたところが、精度を下げたところと、元に戻した(上げた)ところです。
ともに「_」(アンダースコア)が精度変更のサインになります。コードがアンダースコアで終わる場合は精度を下げる(桁を減らす)記号、反対にアンダースコアのあとコードが続く場合は、これまでの桁数にプラスしてアンダースコア以下の桁数を増やすという記号となります。
ここで、アンダースコア直前の文字は、全データと同じであっても省略しないことに注意してください。これにより「アンダースコアから始まる省略データは存在し得ない」というルールができますので、連結時にコードの境界にアンダースコアがある場合(例 AAAA_bbbb)、そのアンダースコアは前のデータに属していることが明確なので、例では(AAAA_ と bbbb)に分離します。(AAAAと _bbbb にはなりません)
詳細はロカポーターのサイトからダウンロードできる仕様書ご覧ください。
これによって、データがさらに圧縮できる場合があります。
この元データの例では、対象となるデータ数が少ないので、ほとんど変わりませんが、少しだけ短くなってきます。
可変精度前(データ部分のみ)
RZHBZwuimjCAjBZmAKnKrGZWqSrRtIoSABWSeyuYCjzELOkfDIBAxcdzuJEAhpNiyGCjqITluWwWxUmaTlz
可変精度適用後(データ部分のみ)
RZHBZwuimjCAjBZmAKnKrGZWqSrRtZ_m_SABWeyYjELkDIBxcdzJEhE_Ni_yGCjqITluWwWxUmaTlz
以上がロカポーターの基本的な仕組みになります。
次回から、ロカポーターがどのような用途に使えるのか、いろいろ検討していきたいと思います。
前回のデータの途中部分、電車の駅の部分は、駅であることが分かれば良いので200mほどの精度でも十分でしょう。この例では手を抜いて本当に駅だけですが、途中経路の形をもう少しこまかく(たとえば高速道路のカタチで)取りたいというような場合、重要度の低い部分を非可逆圧縮にして精度を落とすことで、もう少し圧縮できるようになります。
駅の部分だけ200mの精度(4桁にコード化したもの)にしてみましょう。
ここで、青字にしたところが、精度を下げたところと、元に戻した(上げた)ところです。
ともに「_」(アンダースコア)が精度変更のサインになります。コードがアンダースコアで終わる場合は精度を下げる(桁を減らす)記号、反対にアンダースコアのあとコードが続く場合は、これまでの桁数にプラスしてアンダースコア以下の桁数を増やすという記号となります。
ここで、アンダースコア直前の文字は、全データと同じであっても省略しないことに注意してください。これにより「アンダースコアから始まる省略データは存在し得ない」というルールができますので、連結時にコードの境界にアンダースコアがある場合(例 AAAA_bbbb)、そのアンダースコアは前のデータに属していることが明確なので、例では(AAAA_ と bbbb)に分離します。(AAAAと _bbbb にはなりません)
詳細はロカポーターのサイトからダウンロードできる仕様書ご覧ください。
これによって、データがさらに圧縮できる場合があります。
この元データの例では、対象となるデータ数が少ないので、ほとんど変わりませんが、少しだけ短くなってきます。
可変精度前(データ部分のみ)
RZHBZwuimjCAjBZmAKnKrGZWqSrRtIoSABWSeyuYCjzELOkfDIBAxcdzuJEAhpNiyGCjqITluWwWxUmaTlz
可変精度適用後(データ部分のみ)
RZHBZwuimjCAjBZmAKnKrGZWqSrRtZ_m_SABWeyYjELkDIBxcdzJEhE_Ni_yGCjqITluWwWxUmaTlz
以上がロカポーターの基本的な仕組みになります。
次回から、ロカポーターがどのような用途に使えるのか、いろいろ検討していきたいと思います。
2008/02/19
ロカポーターのしくみ(4)
4.実際の圧縮の例
例として、奈良県香芝市にあるロケージング本社から渋谷にあるゴーガさんへのルートを圧縮してみます。
元データ
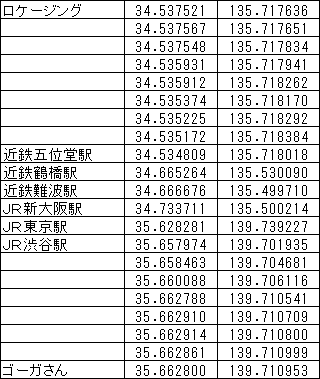
緯度経度をそれぞれコード化すると、次のようになります。コード化の詳細は、別に機会に解説しますが、ここではとりあえず6文字の固定長文字列になることだけ頭においてください。このコードの精度はおよそ1mです。(コード化の手順はロカポーターの仕様書に記述してあります。)
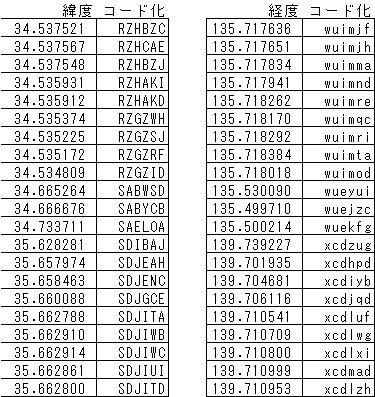
圧縮して、接続する工程は次のようになります。
赤字で示してあるのは圧縮される部分です。
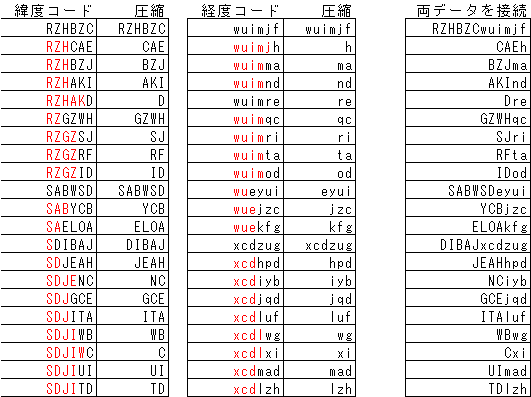
右端の合成値をそのまま接続し、以下のようになります。これが圧縮したデータの部分です。
RZHBZCwuimjfCAEhBZJmaAKIndDreGZWHqcSJriRFtaIDodSABWSDeyuiYCBjzcELOAkfgDIBAJxcdzugJEAHhpdNCiybGCEjqdITAlufWBwgCxiUImadTDlzh
ロカポーターのフォーマット規格は以下のようになっており、圧縮したデータ以外にも、ヘッダ、データセットのデータ種情報とターミネータを付けることが必要です。
● ヘッダの作成
ロカポーターのバージョンは「1.0」なので、整数部分は「1」です。
小数点以下の部分は、下記表にしたがって数字を英文字に置換します。少数以下は「0」なので「A」となります。この両方をつなげて「1A」となります。この変換は次の対応表を使います。

カスタムコードは使用しないので省略します。したがって、ヘッダは「1A」となります。
● データセットのデータ種類
今回のデータは「経路」ですので、2進法で[01]
高度、日時、時刻、カスタムIDとも不使用なので2進法で[0000]
→[010000](2進法) = 16(10進法) = [g]
2進数6ビットから文字への変換は以下の表を使います。
よって、データ種類は「g」となります。
データセットのターミネータ
最後のデータの省略しない表記は「SDJITDxcdlzh」となるので、これをターミネータとします。
これらをまとめると
[ヘッダ][ピリオド][データ種類][データ][ターミネータ]
となるので
「1A.gRZHBZCwuimjfCAEhBZJmaAKIndDreGZWHqcSJriRFtaIDodSABWS
DeyuiYCBjzcELOAkfgDIBAJxcdzugJEAHhpdNCiybGCEjqdITAlufWBwgCxi
UImadTDlzhSDJITDxcdlzh」
がロカポーターとなります。
QRコードにするとこうです。

もし、道案内などの目的で、精度が8m程度でよければ、コード化の際に5桁の固定長文字列になり、次のようになります。
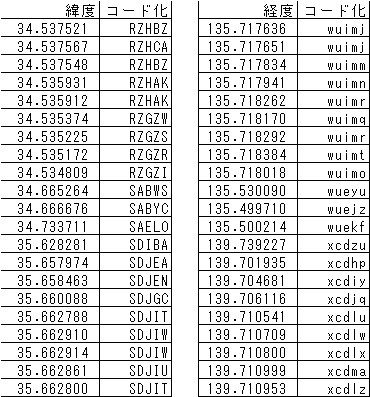
データの圧縮工程は以下のようになります。
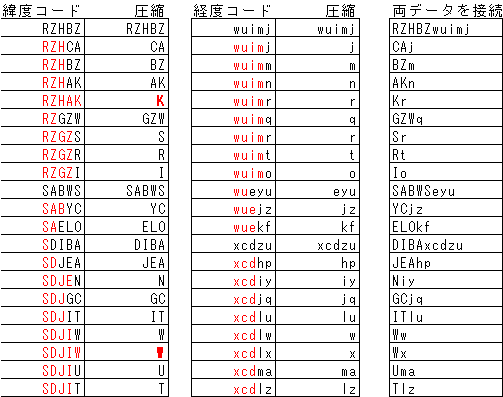
右端の列を連結すると圧縮データになります。左の緯度の表で「K」と「W」が強調されている箇所があります。これは、データが前のデータと全く同じ場合ですが、空文字列にしてしまうとデータの再分離ができなくなるので、緯度経度データの場合、全く前のデータと値が同じ場合でも1文字残す仕様になっています。
圧縮データRZHBZwuimjCAjBZmAKnKrGZWqSrRtIoSABWSeyuYCjzELOkfDIBAxcdzuJEhpNiyGCjqITluWwWxUmaTlz
ターミネータ
SDJITxcdlz
ロカポーター
「1A.gRZHBZwuimjCAjBZmAKnKrGZWqSrRtIoSABWSeyuYCjzELOkfDIBAxcdz
uJEhpNiyGCjqITluWwWxUmaTlzSDJITxcdlz」
QRコードにするとこうなります。

次回は、このデータの途中部分、電車の駅は200mほどの精度でもいいや、という場合の例です。
重要度の低い部分を非可逆圧縮にして精度を落とすことで、もう少し圧縮できるようになります。
例として、奈良県香芝市にあるロケージング本社から渋谷にあるゴーガさんへのルートを圧縮してみます。
元データ
緯度経度をそれぞれコード化すると、次のようになります。コード化の詳細は、別に機会に解説しますが、ここではとりあえず6文字の固定長文字列になることだけ頭においてください。このコードの精度はおよそ1mです。(コード化の手順はロカポーターの仕様書に記述してあります。)
圧縮して、接続する工程は次のようになります。
赤字で示してあるのは圧縮される部分です。
右端の合成値をそのまま接続し、以下のようになります。これが圧縮したデータの部分です。
RZHBZCwuimjfCAEhBZJmaAKIndDreGZWHqcSJriRFtaIDodSABWSDeyuiYCBjzcELOAkfgDIBAJxcdzugJEAHhpdNCiybGCEjqdITAlufWBwgCxiUImadTDlzh
ロカポーターのフォーマット規格は以下のようになっており、圧縮したデータ以外にも、ヘッダ、データセットのデータ種情報とターミネータを付けることが必要です。
● ヘッダの作成
ロカポーターのバージョンは「1.0」なので、整数部分は「1」です。
小数点以下の部分は、下記表にしたがって数字を英文字に置換します。少数以下は「0」なので「A」となります。この両方をつなげて「1A」となります。この変換は次の対応表を使います。
カスタムコードは使用しないので省略します。したがって、ヘッダは「1A」となります。
● データセットのデータ種類
今回のデータは「経路」ですので、2進法で[01]
高度、日時、時刻、カスタムIDとも不使用なので2進法で[0000]
→[010000](2進法) = 16(10進法) = [g]
2進数6ビットから文字への変換は以下の表を使います。
よって、データ種類は「g」となります。
データセットのターミネータ
最後のデータの省略しない表記は「SDJITDxcdlzh」となるので、これをターミネータとします。
これらをまとめると
[ヘッダ][ピリオド][データ種類][データ][ターミネータ]
となるので
「1A.gRZHBZCwuimjfCAEhBZJmaAKIndDreGZWHqcSJriRFtaIDodSABWS
DeyuiYCBjzcELOAkfgDIBAJxcdzugJEAHhpdNCiybGCEjqdITAlufWBwgCxi
UImadTDlzhSDJITDxcdlzh」
がロカポーターとなります。
QRコードにするとこうです。
もし、道案内などの目的で、精度が8m程度でよければ、コード化の際に5桁の固定長文字列になり、次のようになります。
データの圧縮工程は以下のようになります。
右端の列を連結すると圧縮データになります。左の緯度の表で「K」と「W」が強調されている箇所があります。これは、データが前のデータと全く同じ場合ですが、空文字列にしてしまうとデータの再分離ができなくなるので、緯度経度データの場合、全く前のデータと値が同じ場合でも1文字残す仕様になっています。
圧縮データRZHBZwuimjCAjBZmAKnKrGZWqSrRtIoSABWSeyuYCjzELOkfDIBAxcdzuJEhpNiyGCjqITluWwWxUmaTlz
ターミネータ
SDJITxcdlz
ロカポーター
「1A.gRZHBZwuimjCAjBZmAKnKrGZWqSrRtIoSABWSeyuYCjzELOkfDIBAxcdz
uJEhpNiyGCjqITluWwWxUmaTlzSDJITxcdlz」
QRコードにするとこうなります。
次回は、このデータの途中部分、電車の駅は200mほどの精度でもいいや、という場合の例です。
重要度の低い部分を非可逆圧縮にして精度を落とすことで、もう少し圧縮できるようになります。
2008/02/17
ロカポーターのしくみ(3)
3.データ途中の精度変更
高度を考えて見てください。仮にデータが1メートル単位として、地上付近では1メートル精度のデータが欲しい。でも飛行機で上空へ行けば10m単位や100m単位でも問題ない。このデータをどうやって混在させればよいのか。
高度 欲しい精度
00001 1m
00002 1m
00003 1m
00010 10m
00020 10m
00100 10m
01000 1000m
02000 1000m
05000 1000m
ロカポーターには答えがあります。
ロカポータ圧縮の前提は、「固定長文字列であること」ですので、その「固定長」の長さを途中で変えてしまえばいいのです。つまり、
高度 欲しい精度
00001 1m
00002 1m
00003 1m
0001(0) 10m
0002(0) 10m
0010(0) 10m
01(000) 1000m
02(000) 1000m
05(000) 1000m
の3つのセットに分けます。括弧の中は精度を落とせば不要となるデータです。
ところが、単に括弧の中を省略すれだけでは、不十分です。例えば、1000m精度のつもりの「01」が5桁の固定長と思われて「***01」と解釈されてしまいます。
そこで、精度を落とす記号を導入します。
高度 欲しい精度
00001 1m
00002 1m
00003 1m
0001_ 10m <- 固定長5桁をこのデータ以降、1桁落として
(アンダースコアが1つ)固定長4桁に変更
0002 10m
0003 10m
01__ 100m <- 固定長4桁をこのデータ以降、2桁落として
(アンダースコアが2つ)固定長2桁に変更
02 100m
05 100m
省略すると
00001 00001
00002 2
00003 3
0001_ 1_
0002 2
0003 3
01__ 1__
02 2
05 5
仮にこれらのデータをカンマ区切りでつなげてみるとこうなります。
(実際はカンマの部分には緯度経度など他のデータが入り込むことになります。)
00001,2,3,1_,2,3,1__,2,5
ちなみに可変精度を使わないと
00001,2,3,10,20,30,100,200,300
となります。
逆に精度を高めていくには、固定長の長さを増やします。
これにもアンダースコアを使いますが、現データの後に、アンダースコア+増加するデータを加えます。
高度 欲しい精度
05000 1000m
02000 1000m
01000 1000m
00100 10m
00020 10m
00010 10m
00003 1m
00002 1m
00001 1m
上記のデータは精度を変更すると、次のようになる。
高度 欲しい精度
05 1000m
02 1000m
01 1000m
00_10 10m <- 固定長2桁をこのデータ以降、2桁増やして
(アンダースコアの後の値が2つ)固定長4桁に変更
0002 10m
0001 10m
0000_3 1m <- 固定長4桁をこのデータ以降、1桁増やして
(アンダースコアの後の値が1つ)固定長5桁に変更
00002 1m
00001 1m
圧縮すると次のようになる。
05 05
02 2
01 1
00_10 0_10
0002 02
0001 1
0000_3 0_3
00002 2
00001 1
カンマ区切りでつなげてみるとこうなります。
(実際はカンマの部分には緯度経度など他のデータが入り込むことになります。)
05,2,1,0_10,02,1,0_3,2,1
ちなみに可変精度を使わないと
05000,2000,1000,0100,020,10,03,2,1
となります。
圧縮のアイデアは、このように高度のデータについて考えている時に出てきました。
当初は対数を使って、地上付近を密に、上空を粗くするコード体系を用意していたのですが、精度を可変にすることで、1番目のデータのみフル精度が必要であり、あとは好きな桁に落とせば良いことから、もっとも扱いやすい10進法のまま高度を扱うことにしました。
以上の
・固定長データの圧縮
・不定長データの接続
・精度記号によるデータの接続
が基本的なロカポーターの実装に必要なロジックとなります。
続く
高度を考えて見てください。仮にデータが1メートル単位として、地上付近では1メートル精度のデータが欲しい。でも飛行機で上空へ行けば10m単位や100m単位でも問題ない。このデータをどうやって混在させればよいのか。
高度 欲しい精度
00001 1m
00002 1m
00003 1m
00010 10m
00020 10m
00100 10m
01000 1000m
02000 1000m
05000 1000m
ロカポーターには答えがあります。
ロカポータ圧縮の前提は、「固定長文字列であること」ですので、その「固定長」の長さを途中で変えてしまえばいいのです。つまり、
高度 欲しい精度
00001 1m
00002 1m
00003 1m
0001(0) 10m
0002(0) 10m
0010(0) 10m
01(000) 1000m
02(000) 1000m
05(000) 1000m
の3つのセットに分けます。括弧の中は精度を落とせば不要となるデータです。
ところが、単に括弧の中を省略すれだけでは、不十分です。例えば、1000m精度のつもりの「01」が5桁の固定長と思われて「***01」と解釈されてしまいます。
そこで、精度を落とす記号を導入します。
高度 欲しい精度
00001 1m
00002 1m
00003 1m
0001_ 10m <- 固定長5桁をこのデータ以降、1桁落として
(アンダースコアが1つ)固定長4桁に変更
0002 10m
0003 10m
01__ 100m <- 固定長4桁をこのデータ以降、2桁落として
(アンダースコアが2つ)固定長2桁に変更
02 100m
05 100m
省略すると
00001 00001
00002 2
00003 3
0001_ 1_
0002 2
0003 3
01__ 1__
02 2
05 5
仮にこれらのデータをカンマ区切りでつなげてみるとこうなります。
(実際はカンマの部分には緯度経度など他のデータが入り込むことになります。)
00001,2,3,1_,2,3,1__,2,5
ちなみに可変精度を使わないと
00001,2,3,10,20,30,100,200,300
となります。
逆に精度を高めていくには、固定長の長さを増やします。
これにもアンダースコアを使いますが、現データの後に、アンダースコア+増加するデータを加えます。
高度 欲しい精度
05000 1000m
02000 1000m
01000 1000m
00100 10m
00020 10m
00010 10m
00003 1m
00002 1m
00001 1m
上記のデータは精度を変更すると、次のようになる。
高度 欲しい精度
05 1000m
02 1000m
01 1000m
00_10 10m <- 固定長2桁をこのデータ以降、2桁増やして
(アンダースコアの後の値が2つ)固定長4桁に変更
0002 10m
0001 10m
0000_3 1m <- 固定長4桁をこのデータ以降、1桁増やして
(アンダースコアの後の値が1つ)固定長5桁に変更
00002 1m
00001 1m
圧縮すると次のようになる。
05 05
02 2
01 1
00_10 0_10
0002 02
0001 1
0000_3 0_3
00002 2
00001 1
カンマ区切りでつなげてみるとこうなります。
(実際はカンマの部分には緯度経度など他のデータが入り込むことになります。)
05,2,1,0_10,02,1,0_3,2,1
ちなみに可変精度を使わないと
05000,2000,1000,0100,020,10,03,2,1
となります。
圧縮のアイデアは、このように高度のデータについて考えている時に出てきました。
当初は対数を使って、地上付近を密に、上空を粗くするコード体系を用意していたのですが、精度を可変にすることで、1番目のデータのみフル精度が必要であり、あとは好きな桁に落とせば良いことから、もっとも扱いやすい10進法のまま高度を扱うことにしました。
以上の
・固定長データの圧縮
・不定長データの接続
・精度記号によるデータの接続
が基本的なロカポーターの実装に必要なロジックとなります。
続く
2008/02/16
ロカポーターのしくみ(2)
2.圧縮したデータ群の接続方法
ロカポータ圧縮で圧縮した各データは、可変長(というか不定長)のデータの羅列となります。
データが接頭符号であれば、そのまま接続できますし、接尾符号でデータの区切りが分かる場合もそのまま接続できます。
接頭符号など、情報圧縮全般についてはここが詳しい!
しかし、接頭符号でも接尾符号でもないデータをそのまま接続すると、今度分離しようとした時に、どこで分離したらよいか分からず、一意にデータを復元できなくなる恐れがあります。
そのばあい、区切り文字を使うこともできますが、仮にデータが100個あれば区切り文字が1文字としても99文字余分に必要になってしまいます。なんだかもったいない。。。
二進数であれば、このようなデータを接続するには(各データの値が小さい場合は)ワイル(weyl)符号化、ガンマ(γ)符号化、(δ)デルタ符号化、などの方法が良く使われ、これらの符号化により接頭符号化するものです。よく考えられていますね!
ガンマ符号化
デルタ符号化
については、下記サイトの説明が良く分かります。
参考
http://codezine.jp/a/article/aid/475.aspx
CodeZine:δ符号によるデータ領域の節約(CODEC, δ符号, データ圧縮)
さて、ロカポーターでは二進数での処理はせず、文字列で圧縮しているので、文字列ベースでもう少し簡単なものは出来ないか、と考えたのが以下のロカポーターの方式です。
とても単純なアイデアですが、せっかくデータが緯度、経度、高度・・・とあるのでそれぞれを全く違う種類の文字で並べれば人間が目で見ても区切りがすぐわかる。
緯度 経度
5桁固定 ロカポータ 5桁固定 ロカポータ
10030 10030 20013 20012
10028 28 20035 35
10022 2 20135 135
10019 19 20135 (空)→必ず1文字は残すルールにして[5]とする
09998 09998 20029 29
09997 7 20025 5
とします。ここで緯度データの方を 0->A, 1->B, 2->C,,,9->J というように単純に文字を置換します。
緯度 経度
5桁固定 ロカポータ 5桁固定 ロカポータ
10030 BAADA 20013 20012
10028 CI 20035 35
10022 C 20135 135
10019 BJ 20135 5
09998 AJJJI 20029 29
09997 H 20025 5
で、緯度、経度、の順に並べる
BAADA 20012 CI 35 C 135 BJ 5 AJJJI 29 H 5
先ほど、全く同じデータの際でも必ず1文字は残すルールとしたので、このまま接続しても、文字種によってデータの境界が明白なので、区切り文字などを使用しなくても、そのまま接続してOK
BAADA20012CI35C135BJ5AJJJI29H5
できあがり。
分離するときは、文字か数字かで単純に分ける。手作業でもできる!
BAADA 20012 CI 35 C 135 BJ 5 AJJJI 29 H 5
はい、もとどおりです。
なんと単純な仕組みですが、これでも「差分をとって、二進数にして、ガンマ符号にして、最後のホフマン符号で圧縮して、6ビットづつ64進法の文字に戻す」とやる場合と比べて、2倍も差はないです。2倍というのは適当な言い方ですが、仮に10000文字の元データをギュウギュウに圧縮して1000文字とすると、ロカポーター圧縮のような簡易形式でも、たいてい2000文字以内には収まる、という意味です。
ちなみにこの例では、データの種類ごとに使う文字の種類を変えたが、要するにデータの最後の文字と、次のデータの(どこになるかわからない)先頭部分とが違う文字であればOKです。ですので、たとえば、各データを
AAAA0 (Aのところは26進法、0のところは10進法、全部で0~4569759まで)
というロカポのような記述を使うと、最後が数字ひとつとわかっているので
AA0AA0 → (AA)AA0 と(AA)AA0
AAA000 → (A)AAA0 と (AAAA)0 と (AAAA)0
のように、問題なくデータを再分離可能です。
ロカポータでは、この両方の方式を組み合わせています。緯度経度には前者の方式をベースにしたもの、高度や日時などの付加データには後者の方式をベースにしたもの使用しています。
次回は、ロカポーターの目玉である、データ途中の精度変更です。
なお、ご質問等があれば、このブログに投稿頂くか、ロケージングまでお問い合わせください。
それとロカポーターのホームページ(突貫で作ったので、まだ1ページモノですが・・・)からロカポーターの仕様書をダウンロードできるようになっていますので、どうぞご利用ください。
ロカポータ圧縮で圧縮した各データは、可変長(というか不定長)のデータの羅列となります。
データが接頭符号であれば、そのまま接続できますし、接尾符号でデータの区切りが分かる場合もそのまま接続できます。
接頭符号など、情報圧縮全般についてはここが詳しい!
情報と通信のハイパーテキスト(詳しい!)
しかし、接頭符号でも接尾符号でもないデータをそのまま接続すると、今度分離しようとした時に、どこで分離したらよいか分からず、一意にデータを復元できなくなる恐れがあります。
そのばあい、区切り文字を使うこともできますが、仮にデータが100個あれば区切り文字が1文字としても99文字余分に必要になってしまいます。なんだかもったいない。。。
二進数であれば、このようなデータを接続するには(各データの値が小さい場合は)ワイル(weyl)符号化、ガンマ(γ)符号化、(δ)デルタ符号化、などの方法が良く使われ、これらの符号化により接頭符号化するものです。よく考えられていますね!
ワイル符号化
0 表現不可
1~4 0xx
5~8 10xxx
9~16 110xxxx
17~32 1110xxxxx
33~64 11110xxxxxx
65~128 111110xxxxxxx
129~256 1111110xxxxxxxx
:
xxxの部分に数値を2進数で表現したものが入る
(出展:「圧縮アルゴリズム 符号化の原理とC言語による実装」昌達K’z著 ソフトバンクパブリッシング)
ガンマ符号化
デルタ符号化
については、下記サイトの説明が良く分かります。
参考
http://codezine.jp/a/article/aid/475.aspx
CodeZine:δ符号によるデータ領域の節約(CODEC, δ符号, データ圧縮)
さて、ロカポーターでは二進数での処理はせず、文字列で圧縮しているので、文字列ベースでもう少し簡単なものは出来ないか、と考えたのが以下のロカポーターの方式です。
とても単純なアイデアですが、せっかくデータが緯度、経度、高度・・・とあるのでそれぞれを全く違う種類の文字で並べれば人間が目で見ても区切りがすぐわかる。
緯度 経度
5桁固定 ロカポータ 5桁固定 ロカポータ
10030 10030 20013 20012
10028 28 20035 35
10022 2 20135 135
10019 19 20135 (空)→必ず1文字は残すルールにして[5]とする
09998 09998 20029 29
09997 7 20025 5
とします。ここで緯度データの方を 0->A, 1->B, 2->C,,,9->J というように単純に文字を置換します。
緯度 経度
5桁固定 ロカポータ 5桁固定 ロカポータ
10030 BAADA 20013 20012
10028 CI 20035 35
10022 C 20135 135
10019 BJ 20135 5
09998 AJJJI 20029 29
09997 H 20025 5
で、緯度、経度、の順に並べる
BAADA 20012 CI 35 C 135 BJ 5 AJJJI 29 H 5
先ほど、全く同じデータの際でも必ず1文字は残すルールとしたので、このまま接続しても、文字種によってデータの境界が明白なので、区切り文字などを使用しなくても、そのまま接続してOK
BAADA20012CI35C135BJ5AJJJI29H5
できあがり。
分離するときは、文字か数字かで単純に分ける。手作業でもできる!
BAADA 20012 CI 35 C 135 BJ 5 AJJJI 29 H 5
はい、もとどおりです。
なんと単純な仕組みですが、これでも「差分をとって、二進数にして、ガンマ符号にして、最後のホフマン符号で圧縮して、6ビットづつ64進法の文字に戻す」とやる場合と比べて、2倍も差はないです。2倍というのは適当な言い方ですが、仮に10000文字の元データをギュウギュウに圧縮して1000文字とすると、ロカポーター圧縮のような簡易形式でも、たいてい2000文字以内には収まる、という意味です。
ちなみにこの例では、データの種類ごとに使う文字の種類を変えたが、要するにデータの最後の文字と、次のデータの(どこになるかわからない)先頭部分とが違う文字であればOKです。ですので、たとえば、各データを
AAAA0 (Aのところは26進法、0のところは10進法、全部で0~4569759まで)
というロカポのような記述を使うと、最後が数字ひとつとわかっているので
AA0AA0 → (AA)AA0 と(AA)AA0
AAA000 → (A)AAA0 と (AAAA)0 と (AAAA)0
のように、問題なくデータを再分離可能です。
ロカポータでは、この両方の方式を組み合わせています。緯度経度には前者の方式をベースにしたもの、高度や日時などの付加データには後者の方式をベースにしたもの使用しています。
次回は、ロカポーターの目玉である、データ途中の精度変更です。
なお、ご質問等があれば、このブログに投稿頂くか、ロケージングまでお問い合わせください。
それとロカポーターのホームページ(突貫で作ったので、まだ1ページモノですが・・・)からロカポーターの仕様書をダウンロードできるようになっていますので、どうぞご利用ください。
2008/02/15
ロカポーターのしくみ(1)
これから、ロカポーターによる位置情報圧縮の基本的な仕組みを紹介していくことにします。
1.ロカポータ圧縮技術のもっとも基本的な考え方
まず、データはデータ種ごとに、すべて固定長の文字列データにします。
例:5桁(5文字)固定のデータにする場合
元データ 5桁固定
10030 10030
10028 10028
10022 10022
10019 10019
9998 09998
9997 09997
通常、このような数値のデータで、データ値が近いデータ群の圧縮には、差分形式がよく用いられます。
元データ 5桁固定 差分
10030 10030 N/A
10028 10028 -2
10022 10022 -6
10019 10019 -3
9998 09998 -19
9997 09997 -1
ロカポーターでは、差分ではなく、同じ桁を比較して、『文字列の違う箇所』を記述します。
ただし、比較は左側から行い、違う箇所より右は同じ値の場合すべて記述します。
元データ 5桁固定 ロカポータ方式
10030 10030 10030
10028 10028 28
10022 10022 2
10019 10019 19
9998 09998 09998
9997 09997 7
赤字の桁は直前のデータと同じなので、省略する
ちなみにデコードは、上から順に足りない桁を借りてきて埋めるだけ。
固定長と決まっているので、たとえば5桁固定長のところ3桁しかなければ、上位2桁が前のデータと同じ(冗長)と判断する。
ロカポータ
10030 10030
28 10028 ->10028
2 10022 ->10022
19 10019 ->10019
09998 09998 ->09998
7 09997
赤字の桁は、足りないので直前のデータから借りてきて補完した部分。復元したデータは、次のデータの補完の基準となる。
差分方式との違うは、
差分方式の符号処理の場合、2進数なら符号の為に1ビット確保する必要があります。
たとえば固定長データのとりうる値が0~255としましょう。2つのデータの差分のとりうる値は-255~+255ので、510種類の差分値を表す必要があり、9ビットの差分表現領域が必要です。これは元データの255=8ビットから符号の分の桁が増えるためです。
ただし、うまいやり方もあります。
現在の値が100とすれば、次のデータの差分は-100~+155までに限定されます。これは幅が255なので、実質8ビットに抑えられるちう方法もあります。この場合、復号には差分値を足して、255をオーバーした分はマイナス扱いにするなど、一工夫必要です。
ロカポーターの場合は、何の符号制御も必要なく、ただ文字比較をするだけです!
最後の生データの挿入ですが、差分方式だろうとロカポータ方式だろうと、基準とする点に誤差があれば、その誤差は以後のデータに順に引き継がれてしまいます。ですので、時々生データを使い、その間を差分データ等で埋めることになります。ロカポータだと、任意の場所に生データを埋め込むことが出来、しかも生データと圧縮データの違いはデータ長がフルの固定長あるか、それより短いかという違いのみです。
それによって前後の処理が変わることは全く無く、全データを同じアルゴリズムで処理できます。差分方式では、生データか、差分データかという区別するための情報を各データ毎に付加する必要があり、ロカポータではその分、節約できます。
元データ 5桁固定 ロカポータ方式
10030 10030 10030 <-生データ(先頭は必ず生データ))
10028 10028 28 <-圧縮データ
10022 10022 10022 <-生データ(意図的に挿入)
10019 10019 19 <-圧縮データ
9998 09998 09998 <-圧縮データ(結果的に生データと同じ)
9997 09997 7 <-圧縮データ
この方式のデメリットは、たとえば9999と10000のような桁上がり付近のデータ同士の場合、差分なら1で済むところ10000と大きな表現になってしまうことです。
経路情報やエリア情報は、構成する各点の値が少しづつ変化すると考えられるため、単なる数値や数値を表すN進法文字列表現のような、左側に上位桁情報が、右側に下位桁情報がくるような(狭義の単調増加関数である)固定長データを利用すると、左側の桁が同じ値となって省略できる可能性が非常に高くなります。
反面、縦横の座標を基にしたような、メッシュコードなどの文字列では、必ずしも上位桁が左側一方(あるいは右側一方)に偏る可能性が少ないため、この方式による圧縮の効果は少なくなります。
ちなみに、現在N進法でM桁あるとすると、差分を使うと最大M桁の可能性があるのと、符号に1桁使うので、ひとつのデータ当たり最大 log2(Nの(M+1)乗)の情報量となります。ロカポーター方式では桁数は変わらない代わりに同じ場合は空白を使うのでN+1進法のM桁となり、最大 lon2((N+1)のM乗)の情報量となります。どちらがより有利かは N^(M+1) と (N+1)^M の大小関係によりますが、実際のデータによって結果は大きく変わります。
計算してみると、元が2進法の場合、ロカポータ方式のメリットのある可能性は非常に少ないです。ただ、元が10進法などNの値が大きい場合、ロカポータ方式が有効になる場合があります。
次回は、この圧縮したデータ群をどうやってまとめるかについてです。
続く
1.ロカポータ圧縮技術のもっとも基本的な考え方
まず、データはデータ種ごとに、すべて固定長の文字列データにします。
例:5桁(5文字)固定のデータにする場合
元データ 5桁固定
10030 10030
10028 10028
10022 10022
10019 10019
9998 09998
9997 09997
通常、このような数値のデータで、データ値が近いデータ群の圧縮には、差分形式がよく用いられます。
元データ 5桁固定 差分
10030 10030 N/A
10028 10028 -2
10022 10022 -6
10019 10019 -3
9998 09998 -19
9997 09997 -1
ロカポーターでは、差分ではなく、同じ桁を比較して、『文字列の違う箇所』を記述します。
ただし、比較は左側から行い、違う箇所より右は同じ値の場合すべて記述します。
元データ 5桁固定 ロカポータ方式
10030 10030 10030
10028 10028 28
10022 10022 2
10019 10019 19
9998 09998 09998
9997 09997 7
赤字の桁は直前のデータと同じなので、省略する
ちなみにデコードは、上から順に足りない桁を借りてきて埋めるだけ。
固定長と決まっているので、たとえば5桁固定長のところ3桁しかなければ、上位2桁が前のデータと同じ(冗長)と判断する。
ロカポータ
10030 10030
28 10028 ->10028
2 10022 ->10022
19 10019 ->10019
09998 09998 ->09998
7 09997
赤字の桁は、足りないので直前のデータから借りてきて補完した部分。復元したデータは、次のデータの補完の基準となる。
差分方式との違うは、
- 差分方式はプラスマイナスが発生するので、(マイナスの場合は)符号用に1文字必要となること。二進数ではデータごとに1ビットづつ余分に必要となることがあります。ロカポータ方式では、マイナス値は発生しないので、符号処理が不要です。
- 対象が数値ではなく文字列でも、数値演算の必要がなく、文字列の比較のみの簡単な処理で実現できます。
- 上記データの#1、#4のように、圧縮したデータの中に、生のデータを挿入してもまったく処理が破綻しません。
差分方式の符号処理の場合、2進数なら符号の為に1ビット確保する必要があります。
たとえば固定長データのとりうる値が0~255としましょう。2つのデータの差分のとりうる値は-255~+255ので、510種類の差分値を表す必要があり、9ビットの差分表現領域が必要です。これは元データの255=8ビットから符号の分の桁が増えるためです。
ただし、うまいやり方もあります。
現在の値が100とすれば、次のデータの差分は-100~+155までに限定されます。これは幅が255なので、実質8ビットに抑えられるちう方法もあります。この場合、復号には差分値を足して、255をオーバーした分はマイナス扱いにするなど、一工夫必要です。
ロカポーターの場合は、何の符号制御も必要なく、ただ文字比較をするだけです!
最後の生データの挿入ですが、差分方式だろうとロカポータ方式だろうと、基準とする点に誤差があれば、その誤差は以後のデータに順に引き継がれてしまいます。ですので、時々生データを使い、その間を差分データ等で埋めることになります。ロカポータだと、任意の場所に生データを埋め込むことが出来、しかも生データと圧縮データの違いはデータ長がフルの固定長あるか、それより短いかという違いのみです。
それによって前後の処理が変わることは全く無く、全データを同じアルゴリズムで処理できます。差分方式では、生データか、差分データかという区別するための情報を各データ毎に付加する必要があり、ロカポータではその分、節約できます。
元データ 5桁固定 ロカポータ方式
10030 10030 10030 <-生データ(先頭は必ず生データ))
10028 10028 28 <-圧縮データ
10022 10022 10022 <-生データ(意図的に挿入)
10019 10019 19 <-圧縮データ
9998 09998 09998 <-圧縮データ(結果的に生データと同じ)
9997 09997 7 <-圧縮データ
この方式のデメリットは、たとえば9999と10000のような桁上がり付近のデータ同士の場合、差分なら1で済むところ10000と大きな表現になってしまうことです。
経路情報やエリア情報は、構成する各点の値が少しづつ変化すると考えられるため、単なる数値や数値を表すN進法文字列表現のような、左側に上位桁情報が、右側に下位桁情報がくるような(狭義の単調増加関数である)固定長データを利用すると、左側の桁が同じ値となって省略できる可能性が非常に高くなります。
反面、縦横の座標を基にしたような、メッシュコードなどの文字列では、必ずしも上位桁が左側一方(あるいは右側一方)に偏る可能性が少ないため、この方式による圧縮の効果は少なくなります。
ちなみに、現在N進法でM桁あるとすると、差分を使うと最大M桁の可能性があるのと、符号に1桁使うので、ひとつのデータ当たり最大 log2(Nの(M+1)乗)の情報量となります。ロカポーター方式では桁数は変わらない代わりに同じ場合は空白を使うのでN+1進法のM桁となり、最大 lon2((N+1)のM乗)の情報量となります。どちらがより有利かは N^(M+1) と (N+1)^M の大小関係によりますが、実際のデータによって結果は大きく変わります。
計算してみると、元が2進法の場合、ロカポータ方式のメリットのある可能性は非常に少ないです。ただ、元が10進法などNの値が大きい場合、ロカポータ方式が有効になる場合があります。
次回は、この圧縮したデータ群をどうやってまとめるかについてです。
続く
2008/02/13
位置情報圧縮・可搬化技術『LocaPorter(ロカポーター)』発売開始しました
大変お待たせいたしました。
スケジュールが延び延びになっていました『ロカポーター』の発売を、バレンタインデー前日の本日2008年2月13日に開始いたしました。
とりあえず、仕様バージョン1.1ですが、皆さんのご意見を取り入れて、どんどん使いやすいものに変えていきたいと思っています。
よろしければロカポーターのサイトから「ロカポーター仕様書」をご請求ください。
これから、ロカポーターのアルゴリズムを、このブログでも分かり易く解説していきたいと思います。
今後は「位置情報ロカポ」と共に「ロカポーター」も、どうぞよろしくお願いいたします。
ロケージング
代表取締役
上田 直生
スケジュールが延び延びになっていました『ロカポーター』の発売を、バレンタインデー前日の本日2008年2月13日に開始いたしました。
とりあえず、仕様バージョン1.1ですが、皆さんのご意見を取り入れて、どんどん使いやすいものに変えていきたいと思っています。
よろしければロカポーターのサイトから「ロカポーター仕様書」をご請求ください。
これから、ロカポーターのアルゴリズムを、このブログでも分かり易く解説していきたいと思います。
今後は「位置情報ロカポ」と共に「ロカポーター」も、どうぞよろしくお願いいたします。
ロケージング
代表取締役
上田 直生
2008/02/06
ロカポーター誕生の記録(8) 最終回
8.「LocaPorter」名前の由来
開発の経緯の記録の最後に、ロカポーターの名前の由来を残しておきたいと思います。
最初、「ロカポ圧縮」というベタな名前だったこの技術、位置情報系サービス間のパラメータとして使ってほしい、ということでジオメディア2008新年会では「LocaParam」という名前でご紹介させて頂きました。
ところが、LocaPointおよび Locazing(位置情報ロカポで知られてますが、実は「ロケージング」という会社名なんです。)の名付け親でもあるネーミング・コンサルタント Graeme Tickins氏に聞いてみたところ、Paramというのがいまいちしっくりこないとのこと。どうせならParameterの後半のmeterをとって「Locameter」とか「Geometer」にしてはどうかとアドバイスをもらいました。でもgeometerってそのまんま「幾何学の数学者」だし、meterというとメートルと思ってしまいます。インチ・ヤード法の国の方はあまりイメージしないんでしょうかねぇ。
さらにマッシュアップアワードでご一緒させて頂いた、ここギコ!さん!からもロカプレスという名前候補をもらったり、同じくご一緒させて頂いたAN-NAIさんからも「ロカポ」という音がいいので残した法がいい、などいろんな方にアドバイスもらいました。難しいなあ。
いろいろ考えた末、圧縮という特性よりもやはりサービス間の連携能力にフォーカスを当てたかったので、位置情報をLBS間で持ち運ぶ、ポータブルにする、あ、これは番号ポータビリティーならぬ、
位置情報ポータビリティー!
ということで Loca/Geo + Port/Porter/Portable に絞る。GeoportはMACのポート名だし却下。ネーミングコンサルタントのGraemeはLocaPortの方が短いし、Portable も Porterの意味も暗示しているからベターだ、と言ってくれたのだが、私には locaport≒local airport=国内線しか飛んでいない空港みたいに聞こえるし、IT系の人にはそのまんま「ローカルポート」みたいに聞こえる。
Porterの方は、私が鞄好き(といってもウィンドウショッピングだけでほとんど買わないのだが)なので、吉田カバンのPorterのイメージから、本来のポーター(運ぶ人)よりもカバンという印象が強い。
そういう勝手な思い込みと、「運ぶ」ということを前面に出したかったので、最終的に『LocaPorter』に決定!
ちなみに、ここで出てきた名前、取れるものはほとんど全部ドメイン取ってしまった。。無駄なお金を使ってしまいました。
今回はどうでも良い話で失礼しました。
さて、いよいよ次回から、ロカポーターのアルゴリズムの紹介に入っていきたいと思います。
請うご期待!
開発の経緯の記録の最後に、ロカポーターの名前の由来を残しておきたいと思います。
最初、「ロカポ圧縮」というベタな名前だったこの技術、位置情報系サービス間のパラメータとして使ってほしい、ということでジオメディア2008新年会では「LocaParam」という名前でご紹介させて頂きました。
ところが、LocaPointおよび Locazing(位置情報ロカポで知られてますが、実は「ロケージング」という会社名なんです。)の名付け親でもあるネーミング・コンサルタント Graeme Tickins氏に聞いてみたところ、Paramというのがいまいちしっくりこないとのこと。どうせならParameterの後半のmeterをとって「Locameter」とか「Geometer」にしてはどうかとアドバイスをもらいました。でもgeometerってそのまんま「幾何学の数学者」だし、meterというとメートルと思ってしまいます。インチ・ヤード法の国の方はあまりイメージしないんでしょうかねぇ。
さらにマッシュアップアワードでご一緒させて頂いた、ここギコ!さん!からもロカプレスという名前候補をもらったり、同じくご一緒させて頂いたAN-NAIさんからも「ロカポ」という音がいいので残した法がいい、などいろんな方にアドバイスもらいました。難しいなあ。
いろいろ考えた末、圧縮という特性よりもやはりサービス間の連携能力にフォーカスを当てたかったので、位置情報をLBS間で持ち運ぶ、ポータブルにする、あ、これは番号ポータビリティーならぬ、
位置情報ポータビリティー!
ということで Loca/Geo + Port/Porter/Portable に絞る。GeoportはMACのポート名だし却下。ネーミングコンサルタントのGraemeはLocaPortの方が短いし、Portable も Porterの意味も暗示しているからベターだ、と言ってくれたのだが、私には locaport≒local airport=国内線しか飛んでいない空港みたいに聞こえるし、IT系の人にはそのまんま「ローカルポート」みたいに聞こえる。
Porterの方は、私が鞄好き(といってもウィンドウショッピングだけでほとんど買わないのだが)なので、吉田カバンのPorterのイメージから、本来のポーター(運ぶ人)よりもカバンという印象が強い。
そういう勝手な思い込みと、「運ぶ」ということを前面に出したかったので、最終的に『LocaPorter』に決定!
ちなみに、ここで出てきた名前、取れるものはほとんど全部ドメイン取ってしまった。。無駄なお金を使ってしまいました。
今回はどうでも良い話で失礼しました。
さて、いよいよ次回から、ロカポーターのアルゴリズムの紹介に入っていきたいと思います。
請うご期待!
![]()